網站初始
架設網站入門其實很容易,很多網路上的免費資源運用一下,許多學生也可以自己建置網站,最基本的架構就是安裝一台Web server 及一台 Database server,這樣的架構在流量不高的個人網站的確已足夠,但其實風險相當高,因為完全沒考慮到日後的擴充性(scalibility),也沒考慮到系統容錯及復原能力 (High avability & Failover),因此只要流量一高,問題就接踵而至 ,但用這個架構可視為Close beta時期,多找一些親友來當免費測試員。
商業化架構
在這時期代表已經籌到一筆資金,網站可以進行商業化架構設計,一般商業化考量下的標準架構,通常如下圖所示

說明:
Firewall : 專業的防火牆,以Checkpoint 及 Netscreen 為代表 , 很多startup網路公司直接租用IDC提供的防火牆服務或自行架設Proxy server 充當防火牆以低成本。
Load balance server : 分散伺服器負載用 , 可用專業的F5 Big-IP 硬體解決方案或自行安裝軟體如 Apache mod_proxy / Squid來使用 , 目前功能越來越強,也有提供靜態網頁cache功能,有些Proxy server也可以充當Firewall。
Web server : 網頁伺服器 , 又稱 Http server , 常見的有 Apache / IIS / Nginx / GWS / Lighttpd , Niginx 是近期比較受歡迎的Server, 據說效能比Apache更好,但Apache 還是目前市佔率最高的Server。
AP server : 應用伺服器,通常會擺放一些重要的商業邏輯程式, 大都為Java陣營,比較常見的有IBM WebSphere /Red Hat JBoss / Oracle WebLogic / Oracle Glassfish / Apache Tomcat / Apple WebObjects /Adobe JRun / Zend Server for PHP , 微軟的IIS加上.Net framework其實也可稱為AP server , 通常Web server 及 AP server群 都會設Cluster及NLB
DB cluster : 資料庫叢集,設定Cluster 可以做Server redundancy and Failover,不會因為當中的一台DB故障而導致transcation資料遺失,這一波興新的網站大都用My SQL。
DNS server : 設定網域內各server的DNS
Mail server : 發送Mail用
SAN storage : 提供資料庫資料儲存及備份的大型儲存設備,想省錢也可用NAS解決。
這樣的架構對於一般中小型商用網站已足夠,個人預計此時會員大概50萬人左右,頂多在加上監控管理及備份用的伺服器,大部分的SNS或UGC類型網站一開始的設計也是如此,但隨著網站上的資料量及流量不斷成長,就會開始出現網站整體效能不佳的問題,如下所示
Database Loading過重,整體CPU loading 始終維持在80%以上
存放圖片及影音的硬碟Loading過高,顯示很慢
前端網頁很容易出現timeout的錯誤訊息
進入成長期
遇到上列的問題,其時是好消息,表示網站已至成長期,一般網站會開始做下列系統優化,並橫向擴充伺服器群組
1. 資料庫優化
Query優化、索引優化及將負載重的table做反正規化以減少資料庫負荷
建立Master /Slave 資料庫,分散Master主機loading,將讀寫資料庫動作分離,Matster DB只負責被寫入及複製,Slave DB負責被讀取
提升資料庫軟硬體能力,如增加CPU及RAM,將32bit 版本轉為64bit版本。
2. 分散式檔案儲存
建立多個File server , 寫hash function 將上傳的圖片及影音平均分散到File server 上的Folder
3. 建立快取
例如運用 ASP.net 的 cache 儲存資料集
運用PHP APC 建立opcode快取
將不常變動的動態網頁或網頁區塊轉成靜態快取頁面
4. 程式優化
減少大量的資料庫存取介面
若使用PHP 可使用hiphop-php , 加快效率
使用Connection pool加快連上資料庫的速度
使用MVC架構
流量大爆發期
到這個階段表是前面的努力沒有白費,而技術人員每天幾乎都凹到半夜才能回家,調整效能及該擴增的硬體都做了,但因為媒體的大幅報導,還有幾個重量級明星及政客相繼到網站開台,網站流量成爆炸性成長,創投和金主也開始接洽要投資,這時網站會員已到200萬,以該月成長的速度,半年內會到達1000萬人,系統根本無法支撐,若在大幅擴增高階伺服器,其費用很難想像……。
先談談此時系統會發生的問題:
由於網站的巨量,導致存放影音照片的硬碟不勝負荷,讀取及寫入的量已超過其讀寫物理限制,一些存放熱門影音的硬碟,常會因爆量而變得十分緩慢。
資料庫效能以非增加Slave DB能解決,若要轉成大型資料庫中心,費用相當高。
頻寬成本驚人,某個新聞事件發生,網站可能就被人潮灌爆。
我們可以看看一些網站的經驗談:
Youtube :
Myspace :
Facebook:
Performance & caching : Lessons from facebook
Twitter:
NoSQL at Twitter
Facebook、Youtube、Twitter、Myspace 這些流量快速成長的小型公司,都有遇到這爆炸性流量的問題,而且也都樂於分享解決方式,我們可以在網路上找到許多資料,在使用這些技術前我們要先認清這些網站不同於金融或電子交易屬性網站,這類的SNS及UGC網站的資料要求的是速度而非 準確性,其資料量已非Tera(1012 ) 級而是Peta(1015 )級 ,以一般的關聯性資料庫或SAN儲存架構都無法滿足其須快速讀取大量資料的需求,因此衍生了許多目前稱之為雲端運算的技術,這些網站已不是上百台伺服器,而是擁有成千上萬的伺服器,當然大家的疑問是,如何籌到那麼多的資金?我的回答是: 如果網站到達這樣的境界,一堆人抱著錢在排隊。2007年微軟投資Facebook 2.4億美金取得1.6%股權, 無名在到訪率到台灣第一時以7億台幣賣給了台灣Yahoo。
這邊歸納出幾種解決方案
1. memory cache
有別於ASP.net 的Cache散佈在不同的server不能共用也不能互相更新,在資料庫與AP server 中間架設memcached server, 將Profile資料及Friend list 等資料cache在記憶體,會更有效運用記憶體資源。
建議做法為把比較老舊的Server, CPU等級不高硬碟空間較小的Server串接,建立memcached server群組,在MemCached client端建立 consistent hashing機制,來分散各個cache值到各台Server,使用Consistent hashing可以讓日後增加新Server時,不會導致cache存放位置大亂而必須重新到資料庫讀取,造成資料庫瞬間爆量。
其架構如下 : 圖表資料來源 Designing and Implementing Scalable Applications with Memcached and MySQL

其原理可參考下文 : http://forum.homeserver.com.tw/index.php?topic=5.0
當資料庫過大時,還可以用DB Sharding的方式,將Master DB依Customer ID切成多個Shard,來增加效率,有興趣研究的可以參考下面文章。
2. NoSQL
除了一些固定成長,時常需要變動的資料如個人Profile、friend list …等資料外,一些如A在B塗鴉牆留言、A與C變成好友、你follow 的Tweet有了新留言………等,這類資料不停的倍數成長,人一多資料量就超級大,這些資料交由關聯性資料庫處理相當耗時且意義不大,因此就有一些俗稱NoSQL的solution產生。
其概念為,試想太多人讀取單一硬碟的大量檔案,超過了硬碟的IO處理能力怎麼辦,有人想到把檔案切成多個Block碎片,複製並分散到3個不同的儲存節點,有需求的時候在從這些節點中取出組合,這樣就分散了單一硬碟的使用量,而且效率更好,以這樣的概念建立的新的檔案系統基礎,並衍伸出新的資料庫型態
目前主流的平台為
Google開發並使用在多個服務上
Hadoop HDFS / Hive / Hbase
Yahoo及Facebook 都使用Hadoop , Facebook使用HIVE做Data warehouse
Facebook提出的open source架構,目前使用者為Digg,Twitter本來計畫使用卻於2010年7月暫停了轉移計畫
HyperTable
中國百度使用Hadoop HDFS結合HyperTable 的技術,用Mapreduce做搜尋引擎的核心計算。
Kyoto Cabinet / Tokyo Tyrant
日本最大社群網站MIXI就是使用該架構,其他用戶有Plurk及Scribd, Plurk以此架構衍生出新的opensource架構LightCloud
Amazon Dynamo
Amazon 使用的key-value 資料庫,主要應用在儲存best seller lists, shopping carts, customer preferences, session management, sales rank, and product catalog…等資料,目前並沒有對外開放使用。
Voldemort
Linkedin 使用該key-value資料庫
MongoDB
Foursquare為用戶代表,與key-value型態的DB不同的是,MonogoDB支援document型態的資料,如XML儲存,想必Foursquare 用戶的check-in 資料全儲存在MongoDB上了。
這類的Database 大都以key-value 為儲存方式,因此無法用關聯性資料庫的標準語法,來取出資料,也不支援原始資料update,但這樣的架構很適合儲存超大量的資料,如 Twitter 每個人的Timeline 、 Facebook 上的News Feed 、 搜尋引擎Crawl的web 資料、 web game的Notification…..等,這類資料有個特性
1. 不斷的巨量成長
2. 不停的在更新(add new)但不需變動(Update)
3. 隨時需要倒出大量的資料
如果網站有適合的資料,可以考慮這個solution,想必對效能及規模擴增有很大的幫助。
其他相關NoSQL資料請參考 http://nosql-database.org/
3 CDN
當網站使用了memcached及NoSQL DB改善了資料處理效能問題後,大量的照片及影音還是會有效能上的瓶頸,這時就得靠CDN (Content delivery network)公司的解決方案來改善了。
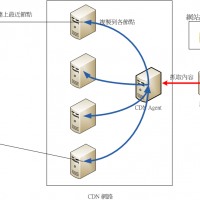
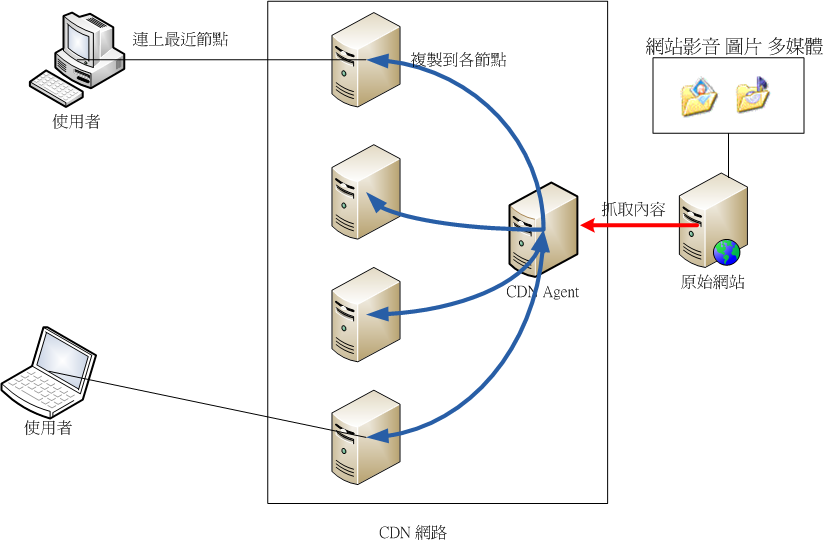
CDN公司大都有超大規模的機房遍部於世界各地,可以幫助其客戶在不用升級設備的狀況下,使用其超大規模的架構把內容散播出去,客戶完全不用擔心伺服器loading的問題,其技術原理如下:
CDN 會定時到客戶網站進行複製並散播到其網路節點去
客戶需要把快取內容的DNS位置指向CDN
使用者連上客戶網站時其實是連到CDN最近的快取節點,不用繞過多層的網路節點。

目前龍頭廠商是Akamai 、LimeLight、LeveL 3 , 但費用也比較高,各國的ISP也都有提供CDN服務,費用較低但全球的節點較少。用戶得依網站的經營型態來考量,以下是一張CDN效能比較表,其實依所在的國別不同,結果也會不一像,大家就當參考。

Youtube 及 Facebook 都有使用到CDN服務 , Facebook 的照片就是用CDN來加速,但由於CDN費用的關係,Facebook建立了新架構Haystack來降低對CDN的依賴
http://www.facebook.com/note.php?note_id=76191543919
結論
我們可以發現,這波的超大型網站都沒用到商用平台,一開始也都不用高檔的商用伺服器,所有的架構都有論文基礎,並且願意Open source出來,Startup公司思考的是用最經濟的方式達到最高效益,而非完全依賴商用平台花錢了事,這種研究精神十分值得敬佩及學習,記得與國內最大網誌的Founder聊到解決流量的方式,他卻一副無可奉告是最高機密的態度,他不也是學術界出來的嗎?可見國內對分享技術這塊還有很大的進步空間。
寫這編文章主要分享一下以往的經驗及學習的心得,希望對大家有一點小幫助。